이 블로그는 실전카프카 개발부터 운영까지 (책만) 책 내용을 스터디를 위해 정리 한 내용 입니다.
책구매는 바로가기 에서 구매 가능합니다.
이번장에서는 카프카를 공부하기 전에 간단히 카프카의 개념에 대해 공부한다.
카프카 기초 다지기
- 주키퍼 : 카프카의 메타데이터 관리 및 브로커의 상태관리(health check)
- 카프카 (kafka cluster) : 카프카 프로젝트 명.
- 브로커 (brocker) : 카프카 어플리케이션이 설치된 서버, 또는 노드.
- 프로듀서 (producer) :카프카로 메시지를 보내는 클라이언트를 총칭
- 컨슈머 (consumer) : 카프카에서 메시지를 꺼내가는 클라이언트 총칭
- 토픽 (topic) : 메시지 피드. 메시지를 관리하는 트레이라고 보는 편이 더 낫다.
- 파티션 (parition) : 메시지 병렬처리를 위한 분할 단위
- 세그먼트 (segment) : 프로듀서가 생성한 메시지를 브로커가 로컬 스토리지에 저장할때 사용되는 파일.
- 메시지 (message) : 주고받는 메시지 조각
리플리케이션
카프카에서 리플리케이션(replication) 이란, 카프카 클로스터내 브로커들에 분산시키는 동작을 의미한다.
토픽이 리플리케이션 되는 것이 아니라, 토픽의 파티션이 리플리케이션 된다.
이로 인해 특정 브로커가 중지되면, 리플리케이션 되어있는 다른 브로커가 업무를 받아 처리 하게된다.
리플리케이션은 많을 수록 안전성이 높아지지만 오버헤드가 그만큼 늘어나게 된다. 일반적으로 개발은 1개로 유지하고, 운영환경의 경우, 유실이 허용되는 시스템은 2개, 신뢰성이 필요한 운영시스템은 3개로 운영한다.
파티션
토픽하나를 여러개로 나눠 병렬 처리가 가능하게 만든 것을 파티션(parition) 이라고한다. 파티션 번호는 0번부터 시작하는데, 아래 그림은 이해상 P1부터로 그려져 있다.
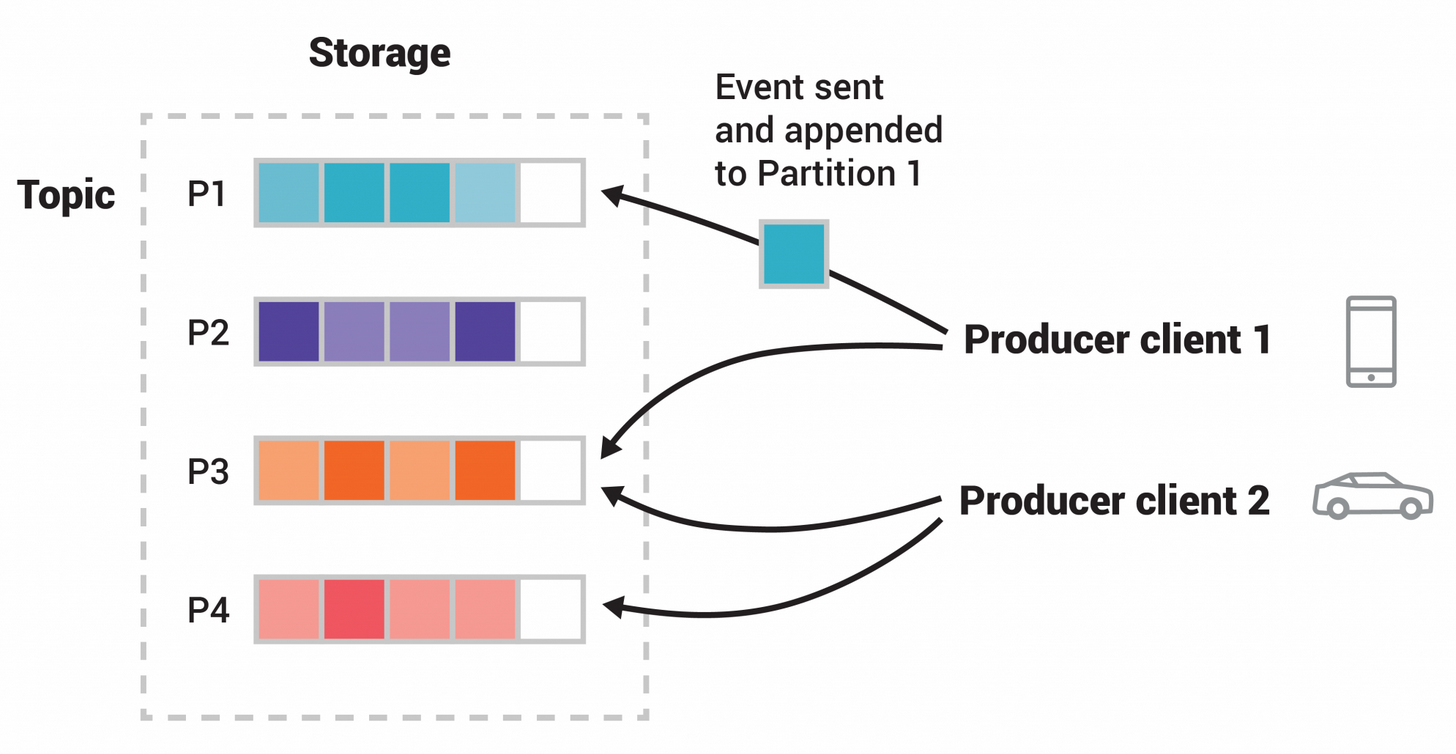
토픽을 파티션을 나눠 관리하면 그만큼 병렬로 프로듀서/컨슈머를 구성할 수 있으므로 좀더 많은 메시지를 더 빨리 처리 할 수 있다.
파티션은 토픽을 생성할때 설정 되며, 한번 설정된 파티션 수는 늘릴수는 있지만, 줄일 수 없다. 일반적으로 처음에는 적게 시작했다가, 시스템 운영상태를 보고 점차 늘려가는 방법을 사용한다.
LAG 란, 처리되는 메시지 양보다 생산되는 메시지 양이 더 많아, 아직 처리할 메시지 개수가 남아있을때, 남아있는 메시지 개수를 LAG라고 부른다. LAG 수를 보고 알맞는 파티션을 찾아 가면된다.
세그먼트 (Segment)
프로듀서에서 생상한 메시지를 브로커가 받게 되면, 브로커는 이 메시지를 세그먼트에 저장한다. 이 세그먼트는 로컬 스토리지에 저장 되는 파일이다. 세그먼트는 파티션 마다 N개가 나뉘어 관리 된다.
카프카의 핵심개념
분산시스템
분산 시스템은 네트워크상에 연결된 여러 서버들이 하나의 시스템 처럼 유기적으로 수행되는 시스템을 말한다. 카프카도 분산 시스템을 지원하며, 서버의 리소스가 한계치에 다다르면 브로커를 추가하는 방식으로 SCALE-OUT 이 가능하다.
페이지 캐시
Kafka 는 브로커에서 메시지를 세그먼트 파일로 저장하기때문에 IO 가 많이 발생하고 이에따라 디스크IO 에 대한 병목이 생긴다.
이때 Kafka 는 OS (Operation System) 의 버퍼캐시(page cache) 를 활용한다. 필요한 부분의 세그먼트 데이터를 디스크 블록정보를 메모리에 저장해두고 메모리영역에서 읽고/쓰기 작업을 하므로써 응답 시간을 줄여 성능을 높인다.
배치 전송 처리
카프카는 프로듀서와 컨슈머에서 메시지를 하나씩 주고받으며 처리하는것이 아니라 여러개 단위로 주고 받는 배치 전송을 한다. 이는 단건 송수신에 따른 오버헤드를 많이 줄일 수 있다.
압축전송
카프카는 압축 전송도 지원한다. 일반적으로 메시지는 텍스트 데이터이기때문에 그냥 송수신 하는것보다 압축하여 송수신 하는것이 더 효과적이다. 압축 타입은 gzip, snappy, lz4, zstd 등을 지원한다.
토픽, 파티션, 오프셋
- 토픽 (topic) : 메시지를 관리하는 단위. 특정 메시지를 지칭한다.
- 파티션 (Partition) : 토픽을 병렬 처리하기 위해 나눈 단위.
- 오프셋 (Offset) : 생성된 메시지가 저장되는 위치를 지칭한다. 메시지 주소값으로 이해하면 된다.
주키퍼의 의존성
주키퍼는 분산 애플리케이션에서 코디네이터의 역할을 담당한다. 카프카 시스템을 여러대 운영할 경우에 필수적으로 필요한 서비스이다. 주키퍼에는 카프카의 메타 데이터가 기록된다.
프로듀서의 기본 동작과 예제 맛보기
프로듀서 디자인
레코드는 토픽, 파티션, key, value로 구성된다. 당연히 key/value 는 필수 이며, 토픽이 파티션으로 구성되었을 경우, 파티션값은 필수이다.
메시지가 프로듀서로 부터 발생하면, Object 는 serializer 로 단계를 거쳐 메시지를 직렬화한다.
이후 파티션이 존재 할 경우, 파티셔너 (partitioner) 를 통해 지정된 파티션으로 레코드를 전달 하며, 파티션이 없을경우, 각 파티션에 라운드-로빈(round-robin) 방식으로 메시지를 전달 한다.
이때 파티션에 메시지를 잠깐 저장 하고 있는데, 메시지가 지정된 단위에 도달 할때까지 기다렸다가 모이면 발송한다. 이는 배치처리를 위함이다.
프로듀서의 주요 옵션
- bootstrap.servers : 클러스터의 호스트, 포트정보
- acks 메시지를 전달 한 뒤, 요청 처리에 대한 완료를 결정하는 옵션.
- buffer.memory : 프로듀서가 메시지를 파티션에 보내기전 잠시 대기할 수 있는 메모리 사이즈
- batch.size : 메시지를 배치 형태로 보낼때, 보내고자 하는 배치 사이즈.
컨슈머의 기본 동작과 예제 맛보기
컨슈머는 토픽에 저장되어 있는 메시지를 가져 오는 역할을 한다.
컨슈머의 기본동작
컨슈머는 브로커에 저장되어 있는 메시지를 가져오는 역할을 한다.
컨슈머는 파티션수와 1:1 로 매핑이된다. 때문에 파티션수보다 많은 컨슈머가 설정되면, 실제 파티션 개수만큼만 수행하게 되고, 나머지 컨슈머는 동작 하지 않는다.
컨슈머의 주요 옵션
- bootstrap.server : 클러스터의 호스트, 포트정보
- fetch.min.byte : 한번에 가지고 올수 있는 최소단위 메시지 크기. 현재 발생한 메시지가 이 단위보다 작으면, 메시지크기가 이 사이즈가 될때까지 기다린다.
- gorup.id : 컨슈머 그룹의 ID.
- max.partition.fetch.bytes : 파티션당 가져올 수 있는 최대 크기
- auto.offset.reset : 카프카에 초기 오프셋이 없거나, 현재 오프셋이 존재하지 않을 경우,
- earliest : 가장 초기값으로 설정
- latest : 가장 나중값으로 설정
- none : 오프셋이 없을 경우 오류 발생
- fetch.max.bytes : 한번에 가져올수 있는 최대 크기.