이전 보다 더 심도 있게 쿼리를 사용해보자. 이번장에서는 두 컬렉션과의 관계 데이터를 추출하는 방식과, 보다 나은 성능을 위한 쿼리까지 알아 볼것이다.
참고 : https://docs.mongodb.com/manual/aggregation/
Aggregation(집계/집합) 프로세스는 데이터를 처리하고, 처리된 결과를 반환하는 프로세스를 말한다. 여러개의 데이터를 를 하나의 기준에서 그룹으로 묶고 하나의 결과로 return 할 수 있다. 이러한 작업을 위해 MongoDB 는 Aggregation Pipeline, map-reduce funtion, 그리고 Single Purpose Aggregation method 를 제공한다.
Aggregation Pipeline
참고 : https://docs.mongodb.com/manual/core/aggregation-pipeline/
여기서 Aggregation Pipeline 은 데이터 프로세스를 모듈별로 처리하는 컨셉이다.
Aggregation pipeline stages
간단히 말하면
"Document > 처리 1단계 > 처리 2단계 > 처리 N단계 > 결과 출력" 와 같은 식으로 처리 하는 방식을 이야기 한다.
예를 들면, 아래와 같이 aggregate 안에 배열로 처리 해야 하는 단계(stage)를 순차적을 입력한다.
db.collection.aggregate( [ { <stage> }, ... ] )순차적으로 입력한 단계는 단계별로 처리가 되고 그 다음으로 데이터를 넘겨, 다음 단계를 수행한다.
이렇게 단계별로 처리 되는 방식이 바로 Aggregation Pipeline (집계 파이프라인) 이다.
참고 : https://docs.mongodb.com/manual/reference/operator/aggregation-pipeline/
aggregation pipeline stage 에서는 다음과 같은 연산자를 제공 한다.
| $match | 지정된 대로 필터링한다. find 와 같다. (stage) |
| $group | 주어진 인수값 기준으로 데이터를 각각 그룹화 한다. (stage) |
| $sort | 특정 필드 기준으로 데이터를 정렬한다. |
| $count | 해당 단계 기준으로 document 개수를 반환한다 |
| $limit | 해당 단계 기준으로 처리된 데이터중 주어진 숫자 만큼 결과를 자른다. |
| $skip | 해당 단계 기준으로 처리된 데이터중 주어진 숫자 만큼 결과를 생략한다. |
위 연산자를 이용해 실제 코드를 구현하자면 다음과 같다.
db.item_base.aggregate([
{$match :{splVenId:'0000100026'}},
{$group :{ _id :'$sellStatCd',
count :{$sum:1}
}
},
{$sort :{_id:1}},
{$skip : 1},
{$limit : 2},
]);1단계 : $match 로 splVenId 가 '0000100026' 인 데이터를 찾고
2단계 : $group 연산자를 통해 sellStatCd가 같은 데이터끼리 묶는다. 그리고 그 개수를 센다.
3단계 : $sort 로 2단계 에서 묶인 데이터를 _id 기준에서 오름차순으로 정렬하며
4단계 : $skip 으로 3단계 정렬된 데이터중 1개 데이터를 건너띄고
5단계 : $limit 로, 마지막 결과중 2개만 순서대로 결과 반환한다.
결과는 다음과 같다.
{
"_id" : "10",
"count" : 39.0
}
{
"_id" : "20",
"count" : 224.0
}사용방법도 어렵지 않고 직관적이다. 이제 연산자를 이용해 데이터를 조회 해보자.
$match
$match 는 이전에 사용하던 find 와 비슷한 역할을 수행한다.
{ $match: { <query> } }find 연산자와 거의 동일한 함수를 사용할 수 있으며, 사용법또한 동일하다.
db.item_base.aggregate([
{$match :{splVenId:'0000100026'}}
]);
$sort, $skip, $limit
$sort, $skip, $limit 연산자도 역시 이전 장에서 배운 내용과 동일하다. 이 연산자를 사용하면, 조회된 데이터를 정렬하고 데이터 결과를 생략하며, 조회된 결과를 제한할 수 있다.
db.item.aggregate([
{$sort :{itemId:-1}},
{$skip : 1},
{$limit : 2},
]);
{
"_id" : ObjectId("61642aa6b177ff22016eb522"),
"itemId" : "1000000000006"
}
{
"_id" : ObjectId("61642aa5b177ff22016eb521"),
"itemId" : "1000000000005"
}
$out / $project
| $out | 조회된 데이터를 새로운 collection 으로 생성한다. 컬렉션이 없으면 새로 생성하고, 있으면 해당 결과로 대체된다. |
| $project | 다음 단계로 넘어갈때, 지정된 필드값만 전달 된다. |
$out 은 처리 결과를 새로운 컬렉션으로 출력한다. 조회된 데이터를 바로 컬렉션으로 생성할 수 있는 기능이다.
또, $project 는 현재 단계에서 처리된 document 의 필드를 주어진 필드만 남기고 전달 한다. 이 두개를 이용해 일반 배열로 구성된 필드를 Document 형으로 바꾼 예제이다.
db.item.aggregate([
{$match :{_id : ObjectId("61642a98b177ff22016eb51d")}},
{$unwind : '$numArray'},
{$project : {_id : 0, 'numArray' : 1}},
{$out :'newCollection'}
]);
db.newCollection.find({});
{
"_id" : ObjectId("6177da4c9deb5b07ebc196bf"),
"numArray" : 1.0
}
{
"_id" : ObjectId("6177da4c9deb5b07ebc196c0"),
"numArray" : 2.0
}
...skip...
{
"_id" : ObjectId("6177da4c9deb5b07ebc196c7"),
"numArray" : 9.0
}$unwind 로 numArray 배열을 Document 로 나눴고, $project 로 동일하게 생성된 _id 를 제거해, 새로운 _id로 생성하게 만들었다. $project 는 이런식으로도 사용되지만, 다음 단계로 전달할때 출력할 필드를 제한해 메모리 사용율을 낮춰 성능을 개선할 수 있다.
$out 연산자는 해당 단계 수행시, 지정된 컬렉션 명이 없을 경우, 컬렉션을 신규로 생성하며, 존재할경우 값을 대체한다. 혹시, 수행중에 파이프라인이 실패 할경우에는, 기존 컬렉션 값은 변경 되지 않는다.
$group
$group 은 주어진 필드 기준으로 데이터를 묶는다. RDBMS 의 group by 기능과 유사하며, 이 연산자를 사용하면 다양한 형태의 집계 데이터를 추출 할 수 있다.
표현 방법은 다음과 같다.
{
$group:
{
_id: <expression>, // Group By Expression
<field1>: { <accumulator1> : <expression1> },
...
}
}
이제 제공되는 연산자 별로 사용법을 알아보자.
Aggregation Pipeline Operators
Accumulators
| $addToSet | 모든 값을 배열로 생성 한다. 단, 중복을 제거한다. |
| $push | 모든 값을 배열로 생성 한다. 단, 중복을 허용한다 |
$addToSet 과 $push 는 group 기준으로 주어진 필드의 값을 배열로 생성한다. 이때, $addToSet 은 중복을 제거하고, $push 는 중복을 허용해 배열을 생성한다는 차이점이 있다.
# $addToSet
db.item_base.aggregate([
{$match :{splVenId:'0000100026'}},
{$group :{ _id :'$splVenId',
sellStatCdTypes :{$addToSet:'$sellStatCd'}
}
}
]);
{
"_id" : "0000100026",
"sellStatCdTypes" : [
"05", "85", "80", "90", "20", "10"
]
}
# $push
db.item_base.aggregate([
{$match :{splVenId:'0000100026'}},
{$group :{ _id :'$splVenId',
sellStatCdTypes :{$push:'$sellStatCd'}
}
}
]);
{
"_id" : "0000100026",
"sellStatCdTypes" : [
"85", "20", "20", "20", "80", "85", "05", "80", ...SKIP..., "20"
]
}
다음은 그룹한뒤 해당 값에 대한 연산 처리이다.
| $avg | 평균값을 계산한다 |
| $count | 그룹 내의 document 개수를 센다 |
| $sum | 그룹의 모든 값의 합계를 구한다. |
| $max | 그룹의 최대값 |
| $min | 그룹의 최저값 |
각 함수는 $group 기준으로 묶인뒤 주어진 값에 따른 갯수, 평균, 최소, 최대 값을 제공한다.
db.item_base.aggregate([
{$match :{splVenId:'0000100026'}},
{$group :{ _id :'$shppRqrmDcnt',
shppRqrmDcnt_count :{$sum:1},
minOnetOrdPsblQty_avg :{$avg:'$minOnetOrdPsblQty'},
minOnetOrdPsblQty_min :{$min:'$minOnetOrdPsblQty'},
minOnetOrdPsblQty_max :{$max:'$minOnetOrdPsblQty'},
}
}
]);
{
"_id" : 3,
"shppRqrmDcnt_count" : 1887.0,
"minOnetOrdPsblQty_avg" : 1.0,
"minOnetOrdPsblQty_min" : NumberLong(1),
"minOnetOrdPsblQty_max" : NumberLong(1)
}
{
"_id" : null,
"shppRqrmDcnt_count" : 133.0,
"minOnetOrdPsblQty_avg" : 1829.75590551181,
"minOnetOrdPsblQty_min" : NumberLong(0),
"minOnetOrdPsblQty_max" : NumberLong(9999)
}
{
"_id" : 5,
"shppRqrmDcnt_count" : 60.0,
"minOnetOrdPsblQty_avg" : 1.0,
"minOnetOrdPsblQty_min" : NumberLong(1),
"minOnetOrdPsblQty_max" : NumberLong(1)
}여기서 눈여겨 보아야 할것은 group 된 Document 의 필드 개수가, RDBMS 와 다르게 $count 가 아닌 $sum: 1로 계산 되었다는 것이다. $sum : 1 은 더해야 할 값에 필드를 지정하지 않고, document 개수 만큼 1을 더하라는 뜻이다.
$count의 경우 (추가 부연설명 필요)
| $first | 그룹의 제일 첫번째 값, (이전에 sort 단계가 있어야 의미 있다) |
| $last | 그룹의 제일 마지막 값 (이전에 sort 단계가 있어야 의미 있다) |
$first, $last 는 해당 단계에서 조회되는 첫번째 값과 마지막 값을 반환한다. 이때 꼭 이전 단계(stage) 에서 sort 명령이 수행 되어야 의미가 있다. 만약 sort 명령이 없다면, 해당 단계에서 조회된 순서대로 결과 값을 return 한다.
$unwind
| $unwind | $unwind은 배열을 확장해 하나의 Document 로 생성 하게 한다 |
$unwind 는 단순하게 생각해서 배열로 입력된 필드를 배열 값 각각을 Document 로 생성한다.
{
"_id" : ObjectId("61642a98b177ff22016eb51d"),
"itemId" : "1000000000001",
"numArray" : [ 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0]
}
db.item.aggregate([
{$match :{_id : ObjectId("61642a98b177ff22016eb51d")}},
{$unwind : '$numArray'}
]);
{
"_id" : ObjectId("61642a98b177ff22016eb51d"),
"itemId" : "1000000000001",
"numArray" : 1.0
}
{
"_id" : ObjectId("61642a98b177ff22016eb51d"),
"itemId" : "1000000000001",
"numArray" : 2.0
}
... skip ...
{
"_id" : ObjectId("61642a98b177ff22016eb51d"),
"itemId" : "1000000000001",
"numArray" : 9.0
}예제에서 알 수 있다싶이, $unwind 값으로 지정된 필드를 제외하곤 동일하게 출력 된다.
아래부턴, 값을 변경하고 계산하는 연산자들이다.
String Expression Operator
| $concat | 두개 이상의 문자열을 하나로 합친다. { $concat: [ <expression1>, <expression2>, ... ] } |
| $strcasecmp | 대소문자를 구분하지 않고 문자열을 비교한다. 결과는 숫자로 반환. { $strcasecmp: [ <expression1>, <expression2> ] } 1 if first string is "greater than" the second string. 0 if the two strings are equal. -1 if the first string is "less than" the second string. |
| $substr | 문자열을 주어진 값만큼 자른다. { $substr: [ <string>, <start>, <length> ] } |
| $toLower | 소문자로 변환한다. { $toLower: <expression> } |
| $toUpper | 대문자로 변환한다 { $toUpper: <expression> } |
| $trim | chars 가 없으면 좌우 공백을 삭제하고, char 이 지정되어 있으면 해당 문자를 삭제한다. { $trim: { input: <string>, chars: <string> } } |
Arithmetic Expression Operator
| $add | 주어진 두 값을 더한다. { $add: [ <expression1>, <expression2>, ... ] } |
| $divide | 1번 값을 2번 값으로 나눈다 { $divide: [ <expression1>, <expression2> ] } |
| $mod | 1번 값을 2번 값으로 나눈 나머지를 구한다 { $mod: [ <expression1>, <expression2> ] } |
| $multiply | 두 값을 더한다. { $multiply: [ <expression1>, <expression2>, ... ] } |
| $subtract | 1번 값에 2번 값만큼 뺀다 { $subtract: [ <expression1>, <expression2> ] } |
| $round | 주어진 값을 입력한 자릿수에서 버린다. { $round : [ <number>, <place> ] } |
Date Expression Operator
| $dateToString | 날짜를 주어진 포멧으로 반환한다. |
| $toDate | 문자열을 입력받아 날짜로 변환한다. |
| $dayOfYear | 날짜 데이터를 입력받아, 연중 몇번째 날인지 반환한다. (1~366) |
| $dayOfMonth | 날짜 데이터를 입력받아, 월중 몇번째 날인지 반환한다. (1~31) |
| $dayOfWeek | 날짜 데이터를 입력받아, 주중 몇번째 날인지 반환한다. (1~7) |
| $year | 날짜 데이터를 입력받아, 연 만 반환한다. |
| $month | 날짜 데이터를 입력받아, 연중 몇번째 월인지 반환한다. (1~12) |
| $week | 날짜 데이터를 입력받아, 연중 몇번째 주인지 반환한다. (0~53) |
| $hour | 날짜 데이터를 입력받아, 시간만 반환한다. (0~23) |
| $minute | 날짜 데이터를 입력받아, 분만 반환한다. (0~60) |
| $second | 날짜 데이터를 입력받아, 초만 반환한다. (0~60) |
| $dateAdd | 날짜를 더한다 |
| $dateDiff | 두 날짜간의 차이를 반환한다 |
날자 연산자는 사용방법이 각기 달라 하나씩 설명하기 어렵다. MongoDB Document 를 참고하도록 하자.
Comparison Expression Operators
| $cmp | 두 값을 비교해 숫자를 반환한다. 첫번째 값이 크면 1, 같으면 0 작으면 -1 |
| $eq | 두 값이 같으면 true 를 반환한다. |
| $gt | 첫번째 값이 크면 true 를 반환한다. |
| $gte | 첫번째 값이 크거나 같으면 true 를 반환한다. |
| $lt | 첫번째 값이 작으면 true 를 반환한다. |
| $lte | 첫번째 값이 작거나 같으면 true 를 반환한다. |
| $ne | 두 값이 다르면 true 를 반환한다. |
Conditional Expression Operators
| $cond | if, then, else 를 사용해 판단 값을 반환한다. { $cond: { if: <boolean-expression>, then: <true-case>, else: <false-case> } } |
| $ifNull | 지정된 값이 null 일 경우에 주어진 값을 반환한다. 5.0 이전에는, 하나의 값만 판단했는데, 5.0 이후부터는 여러개의 값을 지정하여 첫번째 값이 NULL 일경우 두번째, 두번째가 NULL 일경우 세번째, N 번째 까지 지정 가능하게 개선되었다. |
| $switch | switch case 문으로, 지정된 값에 따라 특정 케이스별로 값을 다르게 반환 시킨다. |
Set Expression Operators
| $allElementsTrue | 모든 요소값이 true 일 경우 true 를 반환한다. false 인 요소는 false, 0, undefined 이다 |
| $anyElementTrue | 모든 요소중 하나의 값이라도 true 일 경우 true 를 반환한다. |
| $setDifference | 지정된 배열에, 주어진 배열 조건 값에 없는 값을 반환한다 |
| $setEquals | 중복을 제거 하고 두 배열을 비교해 동일하면 true 를 반환한다. 단, 동일 배열의 차원이 동일해야 한다. |
| $setIntersection | 두 배열의 교배열을 반환한다. |
| $setIsSubset | 첫번째 배열이, 주어진 두번째 배열의 부분 배열 일 경우 true 를 반환한다. |
| $setUnion | 두 배열의 합배열을 반환한다. |
Aggregation Optoion
Aggregation 은 두번째 인자에 몇가지 옵션을 허용 한다.
allowDiskUse
MongoDB 는 각 단계별 100MB 로 메모리 사용을 제한한다. 만약 메모리 사용율이 100MB 를 초과하면 해당 작업은 실패 하게 된다. 이때, 필요한 기능이 allowDiskUse 옵션이다. aggregate 두번째 인수에 {allowDiskUse :true} 를 넣으면 메모리를 초과 하는데이터는 disk를 이용하게 된다. 단, disk 를 사용함으로 써 성능은 그만큼 저하된다.
cursor
Aggregation 의 반환값은 기본적으로 cursor 이다. 하지만 프로그램에서 사용할 경우에는 단일 Document 로 반환된다.
때문에 커서로 반환되지 않을경우 옵션에 커서를 다음과 같이 명시한다
db.item.aggregate([
{$match :{_id : ObjectId("61642a98b177ff22016eb51d")}},
{$unwind : '$numArray'},
{$project : {_id : 0, 'numArray' : 1}},
{$out :'newCollection'}
], {cursor:{}});
기타
MongoDB Join pseudo-join
MongoDB 는 명시적으로 Join은 불가능 하지만, forEach 를 사용하면 Join 한거 같은 효과를 낼 수 있다.
forEach 는 cousor 를 function 으로 반복할 수 있으므로, 조회된 Document 들을 반복 수행하면서 다른 collection 을 조회해 새로운 collection 을 만드는 방식이다. 마치 oracle 의 NL JOIN 과 흡사한 방식이다.
db.item_base.aggregate([
{$match :{splVenId : '0000100026'}}
]).forEach(
function(doc){
var optnDoc = db.itemOptn.aggregate([
{$match :{itemId : doc['itemId']}}
]).next();
doc['optnCnt'] = optnDoc.uitemList.length-1;
db.newItemCollection.insert(doc);
}
);위 예제는 item_base 라는 collection 에서 데이터를 조회 한 다음, 조회된 결과를 forEach 로 반복하여 다시 itemOptn Collection 을 조회해 기존 결과에 추가한뒤 새로운 collection 을 생성한다. 마치 실제 Join 되는것 처럼 결과는 나오지만 그냥 단순히 스크립트를 구현 한 것이다.
이 기능은 function 을 이용해 반복 수행하면서 실제 collection 을 건별로 select 하기 때문에 처리 효율은 그다지 좋치 않다. 가능한 사용을 피하고, 반정규화를 고려 하는 편이 효율 면에서는 더 낫다.
매개변수
복잡한 stage 를 간단히 하기 위해서 다음과 같은 방식도 사용된다.
MongoDB 의 command 는 javascript 방식으로 호출 되므로, 당연히 Document 를 변수로 설정 가능하다.
var vMatch = {splVenId:'0000100026'};
var vGroup = {_id : '$sellStatCd',count :{$sum:1}};
var vSort = {_id:1};
db.item_base.aggregate([
{$match :vMatch},
{$group :vGroup},
{$sort :vSort},
{$skip : 1},
{$limit : 2}
]);당연히 결과는 동일하다.
성능
aggregation pipeline 작업시, 성능에 대해 몇가지 고민 하면서 단계를 적용 해야 한다.
- $match와 $sort 작업시에만 index 사용이 가능하다. 해당 작업 이후에는 index 적용이 되지 않는다.
- 다음 단계로 데이터를 넘길때는, 사용되지 않는 필드는 제거하고 넘겨야 성능을 높일 수 있다.
결국, 단계별로 최대한 데이터를 줄이고, 인덱스를 최대한 사용해야 최종 결과를 빠르게 얻을 수 있다는 것이다.
항상 explain() 을 이용해 실행 계획을 확인 해야 한다.
Map-Reduce function (v5.0 deprecated.)
참고 : https://docs.mongodb.com/manual/core/map-reduce/
Map-Reduce function 은 두단계로 수행된다. 바로 이름에서 알수 있다시피 map단계에서 Document 를 처리하고, Reduce 단계에서 처리된 Document 를 결합한다. 이 기능은 MongoDB 5.0 버전에서 Deprecated 되었다.

위 예제를 하나씩 보면
우선status 가 A 인 데이터를 필터링 하고, map function에 지시된대로 cust_id 기준에서 묶고, amount 값을 배열화한다. 그 다음, reduce function 대로 해당 array 를 모두 더해 최종 cursor 를 return 한다.
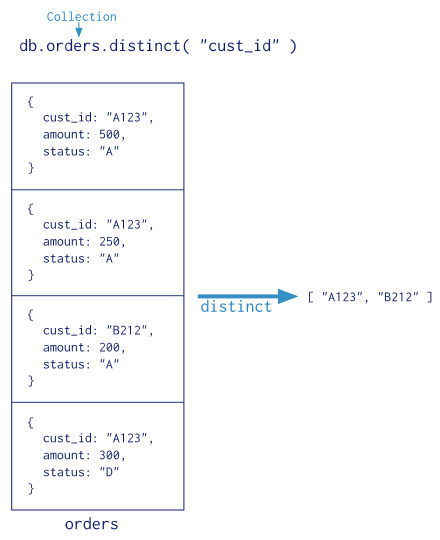
Single Purpose Aggregation method
MongoDB 는 collection 에서 바로 수행 할 수 있는 estimatedDocumentCount(), count(), distinct() 등의 사용법이 간단한 집합 method 도 제공 한다. 아래처럼 distinct 를 간단히 수행 할 수 있다. 간단한 대신에 map-reduce function이나 Aggregation Pipeline 보다 성능은 떨어진다.