들어가기 앞서
본 내용은 MongoDB in Action (몽고디비 인 액션) 2nd Edition 를 참고 하였으며, 그 이외에 참고한 내용에 대해서는 각 개별 링크를 추가 하였습니다.
MongoDB
일반적으로 대부분의 시스템들은 그 양이 많던 적던, 시스템이 관리 해야 할 데이터를 데이터 베이스를 이용하여 관리를 하고 있을 것이다.
많은 데이터를 관리 하기위해, 중복을 피해 정규화 과정을 거치며 여러 테이블로 분리되어 관리하고, 분리된 테이블의 데이터를 고유 키(Primary Key) 로 식별하여 다른 테이블의 특정 key와 관계(Relation) 하여 데이터를 재 조합한다. 이를 관계형 데이터베이스 (RDB : Relational Database) 라고 한다.
이 관계형 데이터 베이스의 경우 각 개별 도메인에의해 제약되어 무결성이 보장되고, 중복을 최소화 하여 설계 하기 때문에 데이터 변경시의 영향을 최소화 할수 있으며, 오류사항을 빠르게 파악 할 수 있다.
그러나, 이러한 장점으로 인한 단점도 존재 한다. 도메인에 의해 제약되어 다양한 데이터 형식을 유동적으로 변환하여 사용할 수 없으며, 중복을 피한 정규화된 데이터를 조회, 관리 해야 하므로 ERD에 대한 이해가 필요하고 복잡한 JOIN 을 사용해야 한다. 또, 개발시에도 단점이 존재 한다. 관계형 데이터베이스는 데이터 모델에 대한 설계과정이 필요하며, 설계가 변경 되었을 경우 생성된 모델의 관계를 고려하여 각 테이블 스키마를 수정 해야 한다.
간단히, MongoDB 는 이러한 단점들을 해결한다.
MongoDB 는 JSON를 이용한 Document 형식으로 데이터를 관리 한다. 복잡한 정규화의 과정없이 하나의 Document 에 모든 데이터를 관리한다.
JSON 은, Key-Value 방식으로 직관적이며, 중첩에 제한이 없다.
ERD에 대한 이해가 없어도, 하나의 데이터 안에 모든 데이터가 존재 하므로 복잡한 조인 과정 없이 어렵지 않게 데이터를 조회 할 수 있다. 때문에 조회 성능이 RDB 보다 우수하다.
또, 각 JSON 은 도메인에 대한 제한이 없어 어렵지 않게 데이터 타입을 변경 할 수 있으며, 스키마 수정없이 새로운 속성 (RDB 에서의 Column) 을 추가 할 수 있다.
MongoDB 의 특징
Document Data Model
아래 데이터는 MongoDB 의 JSON 으로 관리되는 Document 이다. 이는 관계형 데이터 베이스에 해당하는 ROW 에 해당한다.
{
_id : 'dlkzo398d3ed',
itemId : 1000000000123,
itemNm : '상품명'
}JSON 은 기본적으로 {} 로 둘러싸인 KEY-VALUE 형식의 포멧을 따른다. 여기다가, 숫자를 제외한 모든 value는 따옴표(') 로 명시한다. 위 예제는 단순히 KEU-VALUE 가 1:1 형식의 예제이지만, 1:N 데이터도 관리 가능하다.
{
_id: 'dlkzo398d3ed',
itemId: 1000000000123,
tag: ['과일','신선','싱싱'],
mlgtItemNm: [
{
nation: 'kor',
iteNm: '한국어상품명'
},
{
nation: 'eng',
iteNm: '영어상품명'
}
]
}tag 속성과 같이 Array 형식의 N 개의 KEY를 관리 할 수 있으며, mlgtItemNm 과 같이 다른 JSON 형태의 DOCUMENT 를 중첩 사용할 수 있다.
이는 일반적으로 RESTful API 에서 규약된 전문과도 비슷하게 아주 익숙한 형태를 띄고 있다.
내부적으로 MongoDB 는 Binary JSON (BSON) 형태로 Document를 저장한다. BJON 은 JSON 형태의 전문을 Binary 코드로 인코딩한 문자열이다. (참조: https://bsonspec.org/)
스키마 필요 없음.
이러한 Document 방식은 스키마가 따로 필요 없다는 장점이 있다. 이는, 개발 단계에서 변경사항이 발생했을때, 스키마를 수정하는 단계를 생략 시킬 수 있다는 것이다. 도메인모델이 정해지지 않았으므로, 그냥 필요한 속성을 추가하고, 즉시 변경 하면 된다.
애드혹 쿼리 (Ad-HOC Query)
애드혹 쿼리란, 미리 정해지지 않은 질의 사항을 실행 단계에서 지정해 질의 할 수 있는 쿼리 방식을 일컫는다.
예를들어 SQL 표준 쿼리를 보면, 다음과 같이 itemId 를 지정하지 않는다던지, 아니면 ITEM_NM 에 질의 사항을 추가하는 방식을 말한다.
SELEC ITEM_ID, ITEM_NM
FROM ITEM
WHERE ITEM_ID = 1000000000123MongoDB 도 동일한 선상에서 쿼리 사용이 가능하다.
db.test.find({itemId:1000000000123, sellCnt:{'$gt':10}});소스상에서 itemId를 변경 하여 호출 할 수 있으며, 판매개수가 10개 이상인 ($gt) 데이터를 조회조건으로 추가해 질의 할 수 있다.
인덱스 (Index)
MongoDB 는 관계형 DB에서 사용하듯이 INDEX 도 지정 사용 가능하다. 또 다른 Document 형 DB의 경우, 하나의 INDEX 만 허용하는 경우가 많은데, MongoDB 의 경우, 여러개의 Index(Secondary index) 를 지정 가능하다.
MongoDB 는 INDEX 지정시 지정된 컬럼을 기준으로 해당 Document 를 가르키는 포인터 값으로 이루어진 B-TREE 로 INDEX 를 생성한다. B-TREE 는 Balaced Binary search Tree 로, 작은 값은 좌측 트리에, 큰 값은 우측 트리에 위하여 2진 트리를 탐색해 나가는 방식으로 구현된다.
인덱스는 오름/내림차수, 단일(Unique), 복합(Compound), Hash, Text, 지리(Geospatial) 등 다양한 방법으로 제공되며, 한 컬렉션에 최대 64개까지 Secondary Index 생성이 가능하다.
Replica Set (복제)
MongoDB 는 Replica Set (리플리카-셋, 복제세트) 라고 불리는 복제 구성 방식을 제공한다. 이는, 서버 장애가 발생했을때 가능한 빨리 대체 장비로 복구 시킬 수 있는 기능을 제공하며, 읽기 쓰기 등을 분산하여 시스템에 성능을 높일 수 있다.

기본적으로 Primary 는 Application 에서 데이터를 주고 받고, 이를 Secondary 에 동기화 한다.
이때, Primary 에 장애가 발생시, 두 Secondary 는 투표를 진행하여, Secondary 중 하나가 Primary 로 승격 된다.
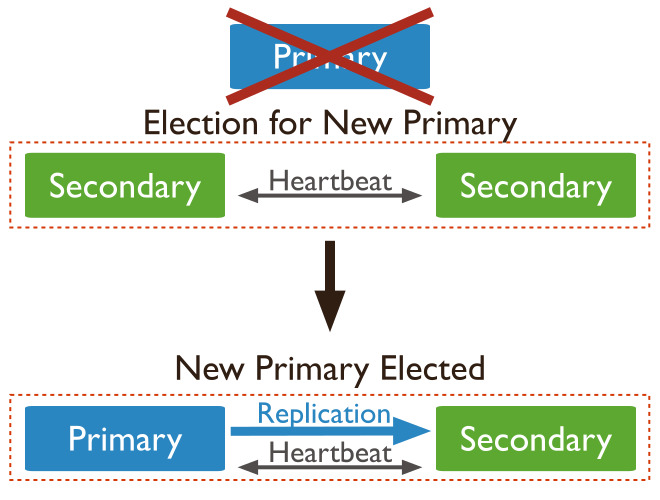
이후 이전 장애가 발생한 장비가 투입되면, 투입된 장비는 secondary 로 동작 하게 됩다.
MongoDB 는 기본적으로 Primary 에서 일기 작업을 진행 한다. Secondary 의 경우 복제작업이 필요하기때문에, Primary 는 항상 최신의 데이터를 return 할 수 있는 장접이 있다. 이때, 구지 최신 데이터가 필요하지 않을 경우 Secondary를 Read Preference 로 설정하여 읽기 분산을 꾀할 수 있다.

참조 : https://docs.mongodb.com/manual/replication/
속도와 내구성
DB는 데이터를 WRITE 하는 메모리 위치에 따라 성능이 좌우된다. 예를들어 RAM 엠 write 하는 경우 와, HDD, SSD 등 스토리지에 직접 write 하는 경우가 그렇다. 이는 최소 10배에서 최대 수백배까지 성능에 차이가 있다.
RAM 에 데이터를 관리 하면 성능은 높지만, 전원이 차단되면 데이터가 삭제되는 단점이 있다. 이에 반해 HDD, 나 SSD 같은 스토리지는 전원이 끊어져도 삭제가 되지 않는 장점이 있다.
예를 들어 REDIS나 MEMCACHED 같은 경우 DB의 경우, RAM 을 이용하기때문에 (설정에따라 다르지만) 성능이 빠른 대신에 장애시 데이터가 사라져 대부분 캐시용도로 사용된다.
MongoDB 는 이 두가지 장단점을 적절하게 조율하여 데이터를 관리한다.
MongoDB 는 쓰기가 메모리에서 발생하고, 특정 시점마다 디스크로 FLUSH 된다. 이때 무결정을 확보 하기 위해 저널링(journaling) 을 이용한다.
저널링(journaling)은 장애가 발생했을때, 복구 할수 있는 방법을 만들어둬 무결성을 확보 하려는것이 목적이다. 사용자에 의해 DATA WRITE 가 발생하면, 사용자에게 응답을 주기 전에 요청한 데이터를 저널파일을 만들어 둔다. 이것으로 장비가 원상 복구 되었을 경우, 해당 로그를 이용해 데이터를 복구하게 된다.
참조 : https://ugong2san.tistory.com/1884
쓰기 시맨틱스(write semantics) ?
(쓰기 시맨틱스에 대한 정보를 찾을 수 없어, 추후 코멘트 하도록 하겠습니다.)
fire-and-forget
fire-and-forget 은 요청 내용에 대한 응답을 확인하지 않는것이다. 네트워크 장비가 정상적이라면 쓰기 요청을 보낸것에 대해 성공으로 예상하고 진행한다는 것이다. 예를들어 Replica set 의 복제작업, commit 등에 대한 확인을 하지 않으므로써, 쓰기에 대한 성능을 높이는 것을 말한다.
(추후 fire and forget 과 저널링과의 관계에 대해 확인하여 추가 코멘트 하도록 하겠습니다.)
확장 (scaling)
MongoDB는 두가지 측면에서의 확장을 할 수 있다.
수직적/상향적 확장 (Vertical scaling, Scaling up) 은 일반적으로 실제 서버을 하드웨어적으로 업그레이드하는 것을 말한다. 메모리 추가, CPU 업그레이드, HDD를 SSD로 변경하는 것 등이 이에 해당한다. 이는 아무래도 각 부품별 최고 성능에 한계가 있으므로 시스템 자체를 업그레이드 하는데에는 한계가 분명 존재한다.

수평적/외적 확장 (scaling horizontally/up) 은 직접적으로 서버를 투입해 데이터를 여러 곳으로 분산 시키는 것을 말한다. 장비를 교체 하지 않고 그대로 사용해 비용적인 측면에서도 이점이 있으며, 데이터를 분산시켜 장애를 최소화 할수도 있어, 대부분 수평적 확장으로 시스템 성능을 향상 시킨다.

이를 위해 MongoDB 는 샤딩(sharding) 을 제공한다. 이는 데이터를 특정범위로 쪼개어 (range-based) 데이터를 여러 노드에 분산하여 관리해주는 기능을 말한다.
MongoDB 코어 서버와 툴
코어서버
MongoDB는 C++ 로 개발되어, 대부분의 OS에서 컴파일되고, 이미 컴파일된 바이너리 파일도 MongoDB 사이트 (http://mongodb.org) 에서 다운 받을 수 있다.
라이센스는 GNU-AGPL로 무료로 사용이 가능하며, 수정할 경우, 해당 수정사항을 공개 하여 배포하여야 한다.
자바스크립트 셀
MongoDB 명령어 셸은 자바스크립트를 사용하여 데이터를 조작하고 관리한다.
다음과 같이 javascript 구문을 이용해 데이터를 insert 할 수 있으며, 역시 데이터를 찾아 조회 할 수 있다.
use test
db.test.insert({itemId:1000000000123});
db.test.find({itemId:1000000000123});
데이터베이스 드라이버
기본적으로 거의 모든 언어의 드라이버를 제공하며, 제 3자 제공 (3rd-party) 라이브러리도 다수 존재한다.
커멘드 라인 툴
mongodump, mongorestor: 백업/복구
mongoexport, mongoimport : JSON, CSV, TSV 타입의 데이터를 impot, export 할 수 있다.
mongotop : lnux의 TOP과 비슷한 기능이다.
mongostat : linux의 iostat 와 비슷한 기능이다
Why MongoDB
MongoDB 와 다른 DB 와 비교
사용의 예
기타
팁과 한계
MongoDB 역사
이상. 김지영.